Archive for the ‘Python’ Category
WSGI初探
此文来自本人原JavaEye博客。原文地址
前言
本文不涉及WSGI的具体协议的介绍,也不会有协议完整的实现,甚至描述中还会掺杂着本人自己对于WSGI的见解。所有的WSGI官方定义请看http://www.python.org/dev/peps/pep-3333/。
WSGI是什么?
WSGI的官方定义是,the Python Web Server Gateway Interface。从名字就可以看出来,这东西是一个Gateway,也就是网关。网关的作用就是在协议之间进行转换。
也就是说,WSGI就像是一座桥梁,一边连着web服务器,另一边连着用户的应用。但是呢,这个桥的功能很弱,有时候还需要别的桥来帮忙才能进行处理。
下面对本文出现的一些名词做定义。wsgi app,又称应用 ,就是一个WSGI application。wsgi container ,又称容器 ,虽然这个部分常常被称为handler,不过我个人认为handler容易和app混淆,所以我称之为容器。 wsgi_middleware ,又称*中间件*。一种特殊类型的程序,专门负责在容器和应用之间干坏事的。
一图胜千言,直接来一个我自己理解的WSGI架构图吧
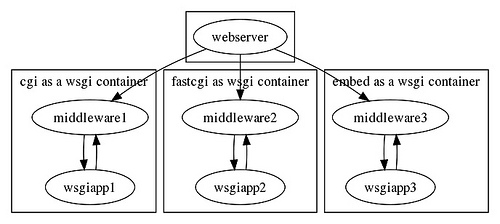
可以看出,服务器,容器和应用之间存在着十分纠结的关系。下面就要把这些纠结的关系理清楚。
WSGI应用
WSGI应用其实就是一个callable的对象。举一个最简单的例子,假设存在如下的一个应用:
def application(environ, start_response):
status = '200 OK'
output = 'World!'
response_headers = [('Content-type', 'text/plain'),
('Content-Length', str(12)]
write = start_response(status, response_headers)
write('Hello ')
return [output]
这个WSGI应用简单的可以用简陋来形容,但是他的确是一个功能完整的WSGI应用。只不过给人留下了太多的疑点,environ是什么?start_response是什么?为什么可以同时用write和return来返回内容?
对于这些疑问,不妨自己猜测一下他的作用。联想到CGI,那么environ可能就是一系列的环境变量,用来表示HTTP请求的信息,比如说method之类的。start_response,可能是接受HTTP response头信息,然后返回一个write函数,这个write函数可以把HTTP response的body返回给客户端。return自然是将HTTP response的body信息返回。不过这里的write和函数返回有什么区别?会不会是其实外围默认调用write对应用返回值进行处理?而且为什么应用的返回值是一个列表呢?说明肯定存在一个对应用执行结果的迭代输出过程。难道说他隐含的支持iterator或者generator吗?
等等,应用执行结果?一个应用既然是一个函数,说明肯定有一个对象去执行它,并且可以猜到,这个对象把environ和start_response传给应用,将应用的返回结果输出给客户端。那么这个对象是什么呢?自然就是WSGI容器了。
WSGI容器
先说说WSGI容器的来源,其实这是我自己编造出来的一个概念。来源就是JavaServlet容器。我个人理解两者有相似的地方,就顺手拿过来用了。
WSGI容器的作用,就是构建一个让WSGI应用成功执行的环境。成功执行,意味着需要传入正确的参数,以及正确处理返回的结果,还得把结果返回给客户端。
所以,WSGI容器的工作流程大致就是,用webserver规定的通信方式,能从webserver获得正确的request信息,封装好,传给WSGI应用执行,正确的返回response。
一般来说,WSGI容器必须依附于现有的webserver的技术才能实现,比如说CGI,FastCGI,或者是embed的模式。
下面利用CGI的方式编写一个最简单的WSGI容器。关于WSGI容器的协议官方文档并没有具体的说如何实现,只是介绍了一些需要约束的东西。具体内容看PEP3333中的协议。
#!/usr/bin/python
#encoding:utf8
import cgi
import cgitb
import sys
import os
#Make the environ argument
environ = {}
environ['REQUEST_METHOD'] = os.environ['REQUEST_METHOD']
environ['SCRIPT_NAME'] = os.environ['SCRIPT_NAME']
environ['PATH_INFO'] = os.environ['PATH_INFO']
environ['QUERY_STRING'] = os.environ['QUERY_STRING']
environ['CONTENT_TYPE'] = os.environ['CONTENT_TYPE']
environ['CONTENT_LENGTH'] = os.environ['CONTENT_LENGTH']
environ['SERVER_NAME'] = os.environ['SERVER_NAME']
environ['SERVER_PORT'] = os.environ['SERVER_PORT']
environ['SERVER_PROTOCOL'] = os.environ['SERVER_PROTOCOL']
environ['wsgi.version'] = (1, 0)
environ['wsgi.url_scheme'] = 'http'
environ['wsgi.input'] = sys.stdin
environ['wsgi.errors'] = sys.stderr
environ['wsgi.multithread'] = False
environ['wsgi.multiprocess'] = True
environ['wsgi.run_once'] = True
#make the start_response argument
#注意,WSGI协议规定,如果没有body内容,是不能返回http response头信息的。
sent_header = False
res_status = None
res_headers = None
def write(body):
global sent_header
if sent_header:
sys.stdout.write(body)
else:
print res_status
for k, v in res_headers:
print k + ': ' + v
print
sys.stdout.write(body)
sent_header = True
def start_response(status, response_headers):
global res_status
global res_headers
res_status = status
res_headers = response_headers
return write
#here is the application
def application(environ, start_response):
status = '200 OK'
output = 'World!'
response_headers = [('Content-type', 'text/plain'),
('Content-Length', str(12)]
write = start_response(status, response_headers)
write('Hello ')
return [output]
#here run the application
result = application(environ, start_response)
for value in result:
write(value)
看吧。其实实现一个WSGI容器也不难。
不过我从WSGI容器的设计中可以看出WSGI的应用设计上面存在着一个重大的问题就是:为什么要提供两种方式返回数据?明明只有一个write函数,却既可以在application里面调用,又可以在容器中传输应用的返回值来调用。如果说让我来设计的话,直接把start_response给去掉了。就用application(environ)这个接口。传一个方法,然后返回值就是status, response_headers和一个字符串的列表。实际传输的方法全部隐藏了。用户只需要从environ中读取数据处理就行了。。
可喜的是,搜了一下貌似web3的标准里面应用的设计和我的想法类似。希望web3协议能早日普及。
Middleware中间件
中间件是一类特殊的程序,可以在容器和应用之间干一些坏事。。其实熟悉python的decorator的人就会发现,这和decoraotr没什么区别。
下面来实现一个route的简单middleware。
class Router(object):
def __init__(self):
self.path_info = {}
def route(self, environ, start_response):
application = self.path_info[environ['PATH_INFO']]
return application(environ, start_response)
def __call__(self, path):
def wrapper(application):
self.path_info[path] = application
return wrapper
这就是一个很简单的路由功能的middleware。将上面那段wsgi容器的代码里面的应用修改成如下:
router = Router()
#here is the application
@router('/hello')
def hello(environ, start_response):
status = '200 OK'
output = 'Hello'
response_headers = [('Content-type', 'text/plain'),
('Content-Length', str(len(output)))]
write = start_response(status, response_headers)
return [output]
@router('/world')
def world(environ, start_response):
status = '200 OK'
output = 'World!'
response_headers = [('Content-type', 'text/plain'),
('Content-Length', str(len(output)))]
write = start_response(status, response_headers)
return [output]
#here run the application
result = router.route(environ, start_response)
for value in result:
write(value)
这样,容器就会自动的根据访问的地址找到对应的app执行了。
延伸
写着写着,怎么越来越像一个框架了?看来Python开发框架真是简单。。
其实从另外一个角度去考虑。如果把application当作是一个运算单元。利用middleware调控IO和运算资源,那么利用WSGI组成一个分布式的系统。
好吧,全文完
Python闭包再研究
此文来自本人原JavaEye博客,原文地址
前两天写了一篇文章,讲了一下Python的闭包。刚好今天又看到一个小问题,和Python闭包有点相关。顺手记录下来。
如下一段代码
funcs = []
for i in xrange(10):
def bar(n):
return n + i
funcs.append(bar)
print funcs[3](5)
这段代码中,我们期望得到的结果是3+5为8。但是实际得到的结果是什么呢?是14。
14是怎么来的?
反汇编看看:
7 0 LOAD_FAST 0 (n)
3 LOAD_GLOBAL 0 (i)
6 BINARY_ADD
7 RETURN_VALUE
注意i是global。
得到14的原因就是,funcs[3]这个函数对象获取i的值,是在执行的时候。而i的作用域是global。也就是说,当这个func开始执行的时候,i已经变成9了。那么结果当然等于14了。
从这个结果看,以上代码和下面代码效果是等价的。
funcs = []
for i in xrange(10):
pass
def bar(n):
return n + i
funcs.append(bar)#这句重复10遍
print funcs[3](5)
很无趣吧。那么考虑一下,如果把i丢到闭包来做会怎样?
funcs = []
def foo(m):
for i in xrange(m):
def bar(n):
return n + i
funcs.append(bar)
foo(10)
print funcs[3](5)
很遗憾,结果依然是14.
反汇编代码如下:
9 0 LOAD_FAST 0 (n)
3 LOAD_DEREF 0 (i)
6 BINARY_ADD
7 RETURN_VALUE
唉,只是傻傻的远程访问而已。
“所有的bar代码中,i仅仅只是在closure中的一个引用而已。指向的依然是同一个对象。当这个对象被改变,所有的bar执行的时候获得的值都是修改后的值”。
顺手写了一段JavaScript来测试,发现结果是一样的。也是会全局改变。具体代码如下:
但是用haskell实现了一个,完全符合预期的结果。
main = do
let funcs = [(\n -> n + i) | i <- [0..9] ]
let x0: x1 : x2: x3: xs = funcs
return (x3 5)
返回结果是8。
看来Python对FP的支持还是比不上Haskell这种正统的函数式语言。
个人觉得如果Python要发展FP的话,可以考虑如下解决方案:区别本地变量和闭包变量。当声明函数的时候将闭包变量拷贝一份到本地,同时保留指向原闭包对象的引用。在搜索名字的时候,始终都是先搜索本地变量,再搜索本地闭包变量副本,再搜索全局变量。当需要修改的时候,如果是本地变量就直接修改。如果是闭包变量的时候,将原来闭包真正指向的对象进行修改,同时覆盖掉本地的闭包副本。
这个方法只是暂时的考虑,没有仔细的推敲。乍看之下似乎可以解决问题。
不过,Python毕竟是OO的语言。没有Haskell或者Lisp那种天生的作用域的控制能力。唉。那就用OO的方式来搞Python把。
Python闭包研究
此文来自本人原JavaEye博客,原文地址
其实很早以前就想写这么一篇文章了。一直没有机会。正好今天和同事讨论Python闭包的问题,趁着没遗忘赶快记录下来。以下代码运行的Python版本是2.5。
问题还是那个很经典的问题:如下代码会抛一个错误
def foo():
a = 1
def bar():
a = a + 1
bar()
print a
错误则是:
UnboundLocalError: local variable 'a' referenced before assignment
原因分析,直接上dis模块解析bar的汇编代码。得到以下结果:
12 0 LOAD_FAST 0 (a)
3 LOAD_CONST 1 (1)
6 INPLACE_ADD
7 STORE_FAST 0 (a)
10 LOAD_CONST 0 (None)
13 RETURN_VALUE
可以看到,造成这个异常的结果是LOAD_FAST没有找到local变量。STORE_FAST语句的作用是绑定一个local变量。那么在储存变量之前就先去读,当然是会报错了。可是,明明是a = a + 1。而按照赋值语句先执行右边的规律来看,他应该先去外层的a那里读取值,然后再新建一个local的名字a,把值赋给local的a啊?
原因暂且放下,先看一段能正常执行的代码。
把前面代码中的a = a + 1改成b = a + 1。反汇编得到以下代码。
13 0 LOAD_DEREF 0 (a)
3 LOAD_CONST 1 (1)
6 BINARY_ADD
7 STORE_FAST 0 (b)
10 LOAD_CONST 0 (None)
13 RETURN_VALUE
果然按照原来设想的一样,a在这个地方变成了LOAD_DEREF,变成了访问外围的值,然后和1想加以后,储存在一个本地的变量b里面。
正确的程序和错误的程序的差别就是,错误的里面,a是赋值语句的左边。
这看起来不经心的一个差别,会不会是原因呢?答案是YES!看python的PEP227中的一段话。
If a name is bound anywhere within a code block, all uses of the name within the block are treated as references to the current block.
这句话非常拗口。我换一种通俗的方式来解释一下。模拟一下python编译器的行为。首先编译器看到了a = a + 1这句话,发现这是一个赋值语句。先检查右边,遇到了一个名字叫做a的东西。a是什么?编译器问自己。会不会是一个局部变量?于是编译器就傻傻的找到规则,规则表说:如果一个名字出现在参数声明,赋值语句(左边),函数声明,类声明,import语句,for语句和except语句中,这就是一个局部变量。ok。编译器从头到尾一看,a就在一个赋值语句的左边,那么a是一个局部变量没跑了。于是生成一条记录LOAD_FAST 0。你是局部变量,让你运行快一点。接着,分析完右边分析左边,赋值语句左边一定是一个局部变量,简单,你就在0号位置把,直接生成STORE_FAST 0,把栈顶的值给你。编译器顺利的编译结束。下面轮到虚拟机运行了。虚拟运行到这个语句就犯糊涂了,叫我LOAD_FAST 0。可是0里面什么东西都没有啊。我擦勒。只好报错了。
而第二段代码为什么能够正确执行呢?其实就是因为,编译器在整个代码块里面没有发现有绑定名字给a,也没有发现a是一个global对象,所以,就生成一个LOAD_DEREF 语句,告诉虚拟机,a不在这个里面。到别的地方去找他。
那么这个别的地方究竟是什么地方呢?如果python没有这个一定是局部变量的规则,是不是就能修改了呢?
我们继续分析。
先找到LOAD_DEREF的定义是什么?查看dis这个模块的说明,里面有如下的文字:
LOAD_DEREF(i)
Loads the cell contained in slot i of the cell and free variable storage. Pushes a reference to the object the cell contains on the stack.
大意就是,加载cell[i]到栈顶。cell是一个什么?这时候,联想到Python的CodeObject里面有一个属性叫做co_cellvars.会不会和这个有关?
查了文档以后发现如下定义
co_cellvars is a tuple containing the names of local variables that are referenced by nested functions;
被嵌套的函数引用的局部变量?好奇特的说法啊。真这么神奇?执行下列代码。
def foo():
a = 1
def bar():
b = a + 1
print 'bar cellvars:', bar.func_code.co_cellvars
foo()
print 'foo cellvars:', foo.func_code.co_cellvars
执行结果是:
bar cellvars: ()
foo cellvars: ('a',)
还真是的,a在bar中引用了,所以被加入到cellvars里面。*需要注意的是,他这里只是把名字放到了cellvar中,也就是说,这个闭包中的对象,依然只是一个引用而已。当这个bar调用的时候,是会顺着引用找到真正的值的。而如果真正的值被修改,在所有的bar里面都会体现。
这个过程是怎么加入的呢?反汇编一下foo的代码:
2 0 LOAD_CONST 1 (1)
3 STORE_DEREF 0 (a)
3 6 LOAD_CLOSURE 0 (a)
9 BUILD_TUPLE 1
12 LOAD_CONST 2 (<code object bar at 0x48f458, file "test.py", line 3>)
15 MAKE_CLOSURE 0
18 STORE_FAST 0 (bar)
21 LOAD_CONST 0 (None)
24 RETURN_VALUE
看到奇特的STORE_DEREF, LOAD_CLOSURE, MAKE_CLOSURE指令。
这三个指令的作用分别如下:
STORE_DEREF(i)
Stores TOS into the cell contained in slot i of the cell and free variable storage.
LOAD_CLOSURE(i)
Pushes a reference to the cell contained in slot i of the cell and free variable storage. The name of the variable is co_cellvars[i]if i is less than the length of co_cellvars. Otherwise it is co_freevars[i - len(co_cellvars)].
MAKE_CLOSURE(argc)
Creates a new function object, sets its func_closure slot, and pushes it on the stack. TOS is the code associated with the function, TOS1 the tuple containing cells for the closure’s free variables. The function also has argc default parameters, which are found below the cells.
看来是编译器发现foo函数里面有一个嵌套的bar函数以后,就把在bar中引用的局部变量a放到一个cell当中,然后将所有的对象都生成成一个tuple,赋值给bar这个funcobject的func_closure。
为了查看神奇的效果,写下面一段代码运行一下看看:
def foo():
a = 1
def bar():
b = a + 1
return bar
b = foo()
print 'bar func_closure:', b.func_closure
如果这程序按照猜测的结果运行,那么将会返回一个cell的tuple。执行结果如下。
bar func_closure: (<cell at 0x454690: int object at 0x803388>,)
果然不出所料。那么func_closure的作用在文档里面怎么描述呢?
func_closure None or a tuple of cells that contain bindings for the function’s free variables. Read-only
看来这个东东涉及到的是Python的名字查找顺序的问题。先local,再闭包,再global。
详细内容可以参看PEP227里面有这么一句话。
The implementation adds several new opcodes and two new kinds of
names in code objects. A variable can be either a cell variable
or a free variable for a particular code object. A cell variable
is referenced by containing scopes; as a result, the function
where it is defined must allocate separate storage for it on each
invocation. A free variable is referenced via a function’s
closure.
The choice of free closures was made based on three factors.
First, nested functions are presumed to be used infrequently,
deeply nested (several levels of nesting) still less frequently.
Second, lookup of names in a nested scope should be fast.
Third, the use of nested scopes, particularly where a function
that access an enclosing scope is returned, should not prevent
unreferenced objects from being reclaimed by the garbage
collector.
相信看到前面func_closure是readonly,大家一定非常失望。看看别的语言的实现如何。
javascript的版本1。
function foo(){
var num = 1;
function bar(){
var num = num + 1;
alert(num);
}
bar()
}
foo();
这个版本会报NaN。。说明Python的问题Javascipt也有。
那如果说num不声明为var呢?
function foo(){
var num = 1;
function bar(){
num = num + 1;
alert(num);
}
bar()
}
foo();
正确提示2.。
要是Python也有这样的机制好了。。
令人高兴的是,python3里面终于改观了。从语法到底层全都支持了(貌似是一个性质)。
语法上加上了nonlocal关键字。
def foo():
a = 1
def bar():
nonlocal a
a = a + 1
print(a)
return bar
foo()()
正确返回2!!
底层加上了可爱的下面两个函数。
PyObject* PyFunction_GetClosure(PyObject *op)¶
Return value: Borrowed reference.
Return the closure associated with the function object op. This can be NULL or a tuple of cell objects.
int PyFunction_SetClosure(PyObject *op, PyObject *closure)
Set the closure associated with the function object op. closure must be Py_None or a tuple of cell objects.
Raises SystemError and returns -1 on failure.
终于可以操作闭包了。哈哈哈哈。。
其实说到最后,如果python中有种机制能支持匿名代码块就好了。嘿嘿。到此结束。
MacOSX下Python2.5版本的locale的编码问题
此文来自本人JavaEye博客,原文地址
今天更新mercurial的时候遇到了一个问题。
执行hg,结果报错:LookupError: unknown encoding: x-mac-simp-chinese
想到这个问题我以前在用django的时候碰到过,原来以为是django的问题,现在才知道原来是普遍的python的问题。
去hg的源代码里面minirst.py里面看了一下,发现是直接调用mercurial的encoding函数的encoding这个变量。
找到encoding.py里面,
try:
encoding = os.environ.get("HGENCODING")
if not encoding:
encoding = locale.getpreferredencoding() or 'ascii'
encoding = _encodingfixers.get(encoding, lambda: encoding)()
except locale.Error:
encoding = 'ascii'
原来是locale这个模块搞的鬼。。
去locale.py里面看了一下,发现以下代码:
if sys.platform in ('win32', 'darwin', 'mac'):
# On Win32, this will return the ANSI code page
# On the Mac, it should return the system encoding;
# it might return "ascii" instead
def getpreferredencoding(do_setlocale = True):
"""Return the charset that the user is likely using."""
import _locale
return _locale._getdefaultlocale()[1]
尝试执行了一下,直接返回了’x-mac-simp-chinese’
为了了解正确的结果,python2.6 -c ‘import locale; print(locale.getpreferredencoding());’返回结果’UTF-8′.
而UTF-8正是我设置的LC_ALL和LANG的结果。
看来是这个_locale模块搞得鬼。不过_locale啊。看名字就是c写的。为了省力。直接把
if sys.platform in ('win32', 'darwin', 'mac'):
改成了
if sys.platform in ('win32'):
然后顺手搜索了一下locale.py中的_locale,把所有的都改了。
执行hg,一切正常。
顺带搜了一下这个问题python的buglist里面有没有,果然看到了。http://bugs.python.org/issue1276。不过略看了一下,发现python2.5.x被无情的忽略了。看来只能自己hack了。:)。
Python中globals对象的回收顺序分析
此文来自本人原JavaEye博客,原文地址
先提示,本文需要一定的python源码基础。许多内容请参考《python源码剖析》。下面切入正题。
今天在群里有人问了一个问题。形如如下的一段程序。
class person:
sum = 0
def __init__(self,name):
self.name=name
person.sum += 1
def __del__(self):
person.sum -= 1
print "%s is leaving" % self.name
a = person('a')
a2 = person('a2')
这段程序的预期的执行结果应该是”a is leaving”和”a2 is leaving”。但是实际上却出乎意料之外,实际的执行结果如下:
a is leaving
Exception exceptions.AttributeError: "'NoneType' object has no attribute 'sum'" in
<bound method person.__del__ of <__main__.person instance at 0x4a18f0>> ignored
为什么引用的名字不同造成的结果会有这么大的差别呢?
分析表面的原因,是person这个引用被指向了None。那他是不是真的是None呢?
__main__.person
None
Exception exceptions.AttributeError: "'NoneType' object has no attribute 'sum'"
in <bound method person.__del__ of <__main__.person instance at 0x4a18c8>> ignored
看来是真的变成了None了。
初步分析原因,应该是程序在执行结束以后,python虚拟机清理环境的时候将”person”这个符号先于”a2″清理了,所以导致在a2的析构函数中无法找到”person”这个符号了。
但是转念一想还是不对,如果是”person”符号找不到了,应该是提示“name ‘person’ is not defined”才对。说明”person”这个符号还在,那”person”指向的class_object对象还在吗?改变程序为以下格式:
class person:
sum = 0
def __init__(self,name):
self.name=name
person.sum += 1
def __del__(self):
#person.sum -= 1
self.__class__.sum -= 1 #1
#print "%s is leaving" % self.name
a = person('a')
a2 = person('a2')
#1就是修改部分,利用自身的__class__来操作。运行结果一切正常。
说明python虚拟机在回收的过程中,只是将”person”这个符号设置成None了。这个结论同时带来2个问题:第一,为什么会设置成None?第二:为什么”person”会先于”a2″而晚于”a”被回收?
先来分析第二个问题。第一反应是不是按照字母的顺序来回收?但是马上这个结论被推翻。”a”和”a2″都在”person”的前面。那么难道是根据globals()这个字典的key顺序来回收?执行一下globals().keys()方法,得到以下结果:
['a', '__builtins__', '__file__', 'person', 'a2', '__name__', '__doc__'];
看来的确是这样。
但是为什么是这样?要得出这个结论,看来只有去python源码中找答案了。
大家都知道,python代码在运行的时候,会存在一个frameobject对象来表示运行时的环境。类似于c语言的栈帧,也有点像lisp的函数的生存空间,看起来答案要从frameobject.c这个文件中去找了。
在frameobject.c中发现了一个函数:static void frame_dealloc(PyFrameObject *f)。看来解决问题的关键就在眼前。
在frame_dealloc里面截取了以下一段代码:
Py_XDECREF(f->f_back);
Py_DECREF(f->f_builtins);
Py_DECREF(f->f_globals);//1
Py_CLEAR(f->f_locals);
Py_CLEAR(f->f_trace);
Py_CLEAR(f->f_exc_type);
Py_CLEAR(f->f_exc_value);
Py_CLEAR(f->f_exc_traceback);
原来减少了引用啊。。关于Py_DECREF这个宏,python源码里面的解释是这样的:
The macros Py_INCREF(op) and Py_DECREF(op) are used to increment or decrement reference counts. Py_DECREF calls the object’s deallocator function when the refcount falls to 0;
这么说来,我们就要去找f_globals的析构函数了。f_globals是个什么呢?当然是PyDictObject了。证据么遍地都是啊,比如随手找了一个,在PyFrameObject * PyFrame_New(PyThreadState *tstate, PyCodeObject *code, PyObject *globals,PyObject *locals)这个函数里面有一段代码:
#ifdef Py_DEBUG
if (code == NULL || globals == NULL || !<span style="color: #ff0000;">PyDict_Check(globals)</span> ||
(locals != NULL && !PyMapping_Check(locals))) {
PyErr_BadInternalCall();
return NULL;
}
#endif
PyDict_Check。。。检查是否是Dict对象。好吧,此处略过,直接奔向dictobject.c看看里面的代码。
static void
dict_dealloc(register dictobject *mp)
{
register dictentry *ep;
Py_ssize_t fill = mp->ma_fill;
PyObject_GC_UnTrack(mp);
Py_TRASHCAN_SAFE_BEGIN(mp)
<span style="color: #ff0000;">for (ep = mp->ma_table; fill > 0; ep++) {
if (ep->me_key) {
--fill;
Py_DECREF(ep->me_key); #
Py_XDECREF(ep->me_value); #仅仅只是引用计数减一
}
}</span>
//以下略
哈哈哈。还真是按照key的顺序来一个一个清除的。
不过,怎么又回到了Py_DECREF啊?
看来最终解释这个问题要回到GC上面了。
其实从这个地方也可以看出第一个问题的答案了,为什么是None?
从上面代码可以看出,dictobject对象在析构的时候,仅仅只是将value的引用计数减一,至于这个对象什么时候被真正回收,其实是由GC决定而不确定的。也就是说为什么是None,是因为减一了以后,凑巧GC到了而已。
根据Python本身的文档。
Warning: Due to the precarious circumstances under which
__del__()methods are invoked, exceptions that occur during their execution are ignored, and a warning is printed to sys.stderr instead. Also, when__del__()is invoked in response to a module being deleted (e.g., when execution of the program is done), other globals referenced by the__del__()method may already have been deleted. For this reason,__del__()methods should do the absolute minimum needed to maintain external invariants. Starting with version 1.5, Python guarantees that globals whose name begins with a single underscore are deleted from their module before other globals are deleted; if no other references to such globals exist, this may help in assuring that imported modules are still available at the time when the__del__()method is called.
Python不能保证_del被调用的时候所有的引用都有,所以,尽量不要overried类的del_方法。
到此结束。
如何使用logger将错误信息输出到日志
此文来自本人原JavaEye博客,原文地址
今天在做分析http错误请求处理的时候遇到一个问题:当发生500错误的时候,如何将错误输出到日志当中呢?
搜了一下python的doc,在logging模块中有不起眼的一行代码提供了解决方案。
mylog.error('error!', exc_info=True)
其中,mylog就是Logger实例,当exc_info设置为True的时候,logger就会自动的调用sys.exc_info()函数,将traceback的信息打印到日志中。
优化Python的DES加密程序有感
此文来自本人原JavaEye博客,发表时间2009年3月24日,可能有些东西现在看来是过时的,甚至是错误的,不过为了保证原来写的时候的感觉,所以没有修改。只在括号中注明了现在的看法。原文地址
最近信息安全的老师布置了作业。要求实现DES算法。。写了1天,优化了1天。。。小有些心得。。
首先感慨一下DES算法。。真是对人对机器都不友好的算法。。竟然还有诡异的S-BOX操作。。。
第二感慨一下Python对2进制不那么方便的支持。。连bin函数都没有。。虽然3.0有了。。可惜2.5没有。。只能自己实现,一大损失效率的地方啊。
好,接下来说说优化过程。
首先是单线程改多线程。。原来是将明文分成64bit一块的序列,每块单独加密。改成每一个64bit的块开一个线程操作。(这个在今天看来完全搞笑)
单线程加密解密一个1000长度的字符串所需时间大致和多线程加密10000长度的相等。效率提升明显。(提升效率很奇怪,忘了自己当初怎么测试的了)
其次是优化异或过程。原来的异或是整体将字符串转成整数然后再异或,发现效率很低。第一次修改为将2个字符串的每一位单独取出转成整形以后异或,效率提升不明显。后来上课时候突然想到,异或操作其实完全可以抛弃整数。1位的2个字符串的异或操作只有4种,写一个字典,用想要异或的2个字符串作为key,结果作为value。简单实现了一下。
def Xor(s1, s2):
"""
字符串xor
s1 -- 第一个字符串
s2 -- 第二个字符串
"""
data={}
data['0','1']=data['1','0']='1'
data['0','0']=data['1','1']='0'
s=[data[s1[x],s2[x]] for x in range(0,s1.__len__())]
return ''.join(s)
三就是优化10进制转2进制。因为python没有提供 bin 函数。于是自己实现了一个。
dec2bin = lambda n:''.join([hex2bin(x) for x in hex(n)[2:].rstrip('L')]
但是在用profile做测试的时候发现的。程序运行中大量的用到了这个函数。很占cpu时间。经过观察发现主要是2个地方使用很多,第一就是异或操作的时候,因为python提供的异或只能在整数之间进行,第二就是在S_BOX运算的时候。
异或操作已经优化了。不需要10进制转2进制了。。剩下就是S_BOX运算了。经过观察发现,S_BOX里面最大的数也不过 15,于是想到可以穷举所有S_BOX里面的数字的值对应的二进制。更改代码如下。
def easyDec2Bin(s):
"""
简单的10进制转2进制,用于简化s_box操作
s -- 10进制数
"""
data={0:'0000',1:'0001',2:'0010',3:'0011',4:'0100',
5:'0101',6:'0110',7:'0111',8:'1000',9:'1001',
10:'1010',11:'1011',12:'1100',13:'1101',14:'1110',
15:'1111'}
return data[s]
第四步优化也是通过profile发现的。。发现程序运行过程中,大量的时间消耗在一个lambda函数上。
b= ''.join(map(lambda x:data[x],s))
这个函数的作用是生成一个字符串。。尝试着把这个lambda函数改成列表操作。
b= ''.join([data[x] for x in s]
效率提升明显。。。原来一直以为map操作比较快。看来并非如此。难怪Guido大叔要推广列表操作了。。
最后一步优化就是用了psyco模块,将程序变成JIT的。。效率提升很大。。。(现在看来其实这一步是最关键的。自己当初好傻)
最终优化的结果就是,加密解密1个40k的文件,原本需要将近50秒的时间,现在10秒不到就完成了。。。。
效果提升明显。不过总觉得还有提升的空间。。尝试把多线程改成Stackless版本的试试看。。。。希望能有更大的提高 。。。。(这句话现在看来完全是搞笑,看来当时的自己还是很稚嫩啊)
使用greenlet中一点简单心得
想要对greenlet的switch机制进行测试,于是写了以下这段代码。
from greenlet import *
def test1(x, y):
print 'in test1'
z = gr2.switch(x+y)
print z
print 'out test1'
def test2(u):
print 'in test2'
print u
gr1.switch(42)
print 'out test1'
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch("hello", " world")
运行结果:
in test1
in test2
hello world
42
out test1
从这个层面可以看出。greenlet的协程其实是一个切换机制。就是主动将自己的运行过程让给别的协程。切换需要有目标,并且可以在switch里面传入参数。如果是第一次运行,switch的参数就是作为协程的run的函数的参数传入。如果是运行中,就作为switch的返回值。
以上隐含的内容是,如果在运行中想要切换到别的协程去做事,那么不能保证那个协程一定会返回结果。
考虑在greenlet上面加上一个隐含回复机制。

