Archive for 三月, 2011
WSGI初探
此文来自本人原JavaEye博客。原文地址
前言
本文不涉及WSGI的具体协议的介绍,也不会有协议完整的实现,甚至描述中还会掺杂着本人自己对于WSGI的见解。所有的WSGI官方定义请看http://www.python.org/dev/peps/pep-3333/。
WSGI是什么?
WSGI的官方定义是,the Python Web Server Gateway Interface。从名字就可以看出来,这东西是一个Gateway,也就是网关。网关的作用就是在协议之间进行转换。
也就是说,WSGI就像是一座桥梁,一边连着web服务器,另一边连着用户的应用。但是呢,这个桥的功能很弱,有时候还需要别的桥来帮忙才能进行处理。
下面对本文出现的一些名词做定义。wsgi app,又称应用 ,就是一个WSGI application。wsgi container ,又称容器 ,虽然这个部分常常被称为handler,不过我个人认为handler容易和app混淆,所以我称之为容器。 wsgi_middleware ,又称*中间件*。一种特殊类型的程序,专门负责在容器和应用之间干坏事的。
一图胜千言,直接来一个我自己理解的WSGI架构图吧
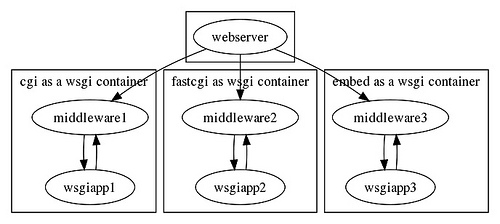
可以看出,服务器,容器和应用之间存在着十分纠结的关系。下面就要把这些纠结的关系理清楚。
WSGI应用
WSGI应用其实就是一个callable的对象。举一个最简单的例子,假设存在如下的一个应用:
def application(environ, start_response):
status = '200 OK'
output = 'World!'
response_headers = [('Content-type', 'text/plain'),
('Content-Length', str(12)]
write = start_response(status, response_headers)
write('Hello ')
return [output]
这个WSGI应用简单的可以用简陋来形容,但是他的确是一个功能完整的WSGI应用。只不过给人留下了太多的疑点,environ是什么?start_response是什么?为什么可以同时用write和return来返回内容?
对于这些疑问,不妨自己猜测一下他的作用。联想到CGI,那么environ可能就是一系列的环境变量,用来表示HTTP请求的信息,比如说method之类的。start_response,可能是接受HTTP response头信息,然后返回一个write函数,这个write函数可以把HTTP response的body返回给客户端。return自然是将HTTP response的body信息返回。不过这里的write和函数返回有什么区别?会不会是其实外围默认调用write对应用返回值进行处理?而且为什么应用的返回值是一个列表呢?说明肯定存在一个对应用执行结果的迭代输出过程。难道说他隐含的支持iterator或者generator吗?
等等,应用执行结果?一个应用既然是一个函数,说明肯定有一个对象去执行它,并且可以猜到,这个对象把environ和start_response传给应用,将应用的返回结果输出给客户端。那么这个对象是什么呢?自然就是WSGI容器了。
WSGI容器
先说说WSGI容器的来源,其实这是我自己编造出来的一个概念。来源就是JavaServlet容器。我个人理解两者有相似的地方,就顺手拿过来用了。
WSGI容器的作用,就是构建一个让WSGI应用成功执行的环境。成功执行,意味着需要传入正确的参数,以及正确处理返回的结果,还得把结果返回给客户端。
所以,WSGI容器的工作流程大致就是,用webserver规定的通信方式,能从webserver获得正确的request信息,封装好,传给WSGI应用执行,正确的返回response。
一般来说,WSGI容器必须依附于现有的webserver的技术才能实现,比如说CGI,FastCGI,或者是embed的模式。
下面利用CGI的方式编写一个最简单的WSGI容器。关于WSGI容器的协议官方文档并没有具体的说如何实现,只是介绍了一些需要约束的东西。具体内容看PEP3333中的协议。
#!/usr/bin/python
#encoding:utf8
import cgi
import cgitb
import sys
import os
#Make the environ argument
environ = {}
environ['REQUEST_METHOD'] = os.environ['REQUEST_METHOD']
environ['SCRIPT_NAME'] = os.environ['SCRIPT_NAME']
environ['PATH_INFO'] = os.environ['PATH_INFO']
environ['QUERY_STRING'] = os.environ['QUERY_STRING']
environ['CONTENT_TYPE'] = os.environ['CONTENT_TYPE']
environ['CONTENT_LENGTH'] = os.environ['CONTENT_LENGTH']
environ['SERVER_NAME'] = os.environ['SERVER_NAME']
environ['SERVER_PORT'] = os.environ['SERVER_PORT']
environ['SERVER_PROTOCOL'] = os.environ['SERVER_PROTOCOL']
environ['wsgi.version'] = (1, 0)
environ['wsgi.url_scheme'] = 'http'
environ['wsgi.input'] = sys.stdin
environ['wsgi.errors'] = sys.stderr
environ['wsgi.multithread'] = False
environ['wsgi.multiprocess'] = True
environ['wsgi.run_once'] = True
#make the start_response argument
#注意,WSGI协议规定,如果没有body内容,是不能返回http response头信息的。
sent_header = False
res_status = None
res_headers = None
def write(body):
global sent_header
if sent_header:
sys.stdout.write(body)
else:
print res_status
for k, v in res_headers:
print k + ': ' + v
print
sys.stdout.write(body)
sent_header = True
def start_response(status, response_headers):
global res_status
global res_headers
res_status = status
res_headers = response_headers
return write
#here is the application
def application(environ, start_response):
status = '200 OK'
output = 'World!'
response_headers = [('Content-type', 'text/plain'),
('Content-Length', str(12)]
write = start_response(status, response_headers)
write('Hello ')
return [output]
#here run the application
result = application(environ, start_response)
for value in result:
write(value)
看吧。其实实现一个WSGI容器也不难。
不过我从WSGI容器的设计中可以看出WSGI的应用设计上面存在着一个重大的问题就是:为什么要提供两种方式返回数据?明明只有一个write函数,却既可以在application里面调用,又可以在容器中传输应用的返回值来调用。如果说让我来设计的话,直接把start_response给去掉了。就用application(environ)这个接口。传一个方法,然后返回值就是status, response_headers和一个字符串的列表。实际传输的方法全部隐藏了。用户只需要从environ中读取数据处理就行了。。
可喜的是,搜了一下貌似web3的标准里面应用的设计和我的想法类似。希望web3协议能早日普及。
Middleware中间件
中间件是一类特殊的程序,可以在容器和应用之间干一些坏事。。其实熟悉python的decorator的人就会发现,这和decoraotr没什么区别。
下面来实现一个route的简单middleware。
class Router(object):
def __init__(self):
self.path_info = {}
def route(self, environ, start_response):
application = self.path_info[environ['PATH_INFO']]
return application(environ, start_response)
def __call__(self, path):
def wrapper(application):
self.path_info[path] = application
return wrapper
这就是一个很简单的路由功能的middleware。将上面那段wsgi容器的代码里面的应用修改成如下:
router = Router()
#here is the application
@router('/hello')
def hello(environ, start_response):
status = '200 OK'
output = 'Hello'
response_headers = [('Content-type', 'text/plain'),
('Content-Length', str(len(output)))]
write = start_response(status, response_headers)
return [output]
@router('/world')
def world(environ, start_response):
status = '200 OK'
output = 'World!'
response_headers = [('Content-type', 'text/plain'),
('Content-Length', str(len(output)))]
write = start_response(status, response_headers)
return [output]
#here run the application
result = router.route(environ, start_response)
for value in result:
write(value)
这样,容器就会自动的根据访问的地址找到对应的app执行了。
延伸
写着写着,怎么越来越像一个框架了?看来Python开发框架真是简单。。
其实从另外一个角度去考虑。如果把application当作是一个运算单元。利用middleware调控IO和运算资源,那么利用WSGI组成一个分布式的系统。
好吧,全文完
Python闭包再研究
此文来自本人原JavaEye博客,原文地址
前两天写了一篇文章,讲了一下Python的闭包。刚好今天又看到一个小问题,和Python闭包有点相关。顺手记录下来。
如下一段代码
funcs = []
for i in xrange(10):
def bar(n):
return n + i
funcs.append(bar)
print funcs[3](5)
这段代码中,我们期望得到的结果是3+5为8。但是实际得到的结果是什么呢?是14。
14是怎么来的?
反汇编看看:
7 0 LOAD_FAST 0 (n)
3 LOAD_GLOBAL 0 (i)
6 BINARY_ADD
7 RETURN_VALUE
注意i是global。
得到14的原因就是,funcs[3]这个函数对象获取i的值,是在执行的时候。而i的作用域是global。也就是说,当这个func开始执行的时候,i已经变成9了。那么结果当然等于14了。
从这个结果看,以上代码和下面代码效果是等价的。
funcs = []
for i in xrange(10):
pass
def bar(n):
return n + i
funcs.append(bar)#这句重复10遍
print funcs[3](5)
很无趣吧。那么考虑一下,如果把i丢到闭包来做会怎样?
funcs = []
def foo(m):
for i in xrange(m):
def bar(n):
return n + i
funcs.append(bar)
foo(10)
print funcs[3](5)
很遗憾,结果依然是14.
反汇编代码如下:
9 0 LOAD_FAST 0 (n)
3 LOAD_DEREF 0 (i)
6 BINARY_ADD
7 RETURN_VALUE
唉,只是傻傻的远程访问而已。
“所有的bar代码中,i仅仅只是在closure中的一个引用而已。指向的依然是同一个对象。当这个对象被改变,所有的bar执行的时候获得的值都是修改后的值”。
顺手写了一段JavaScript来测试,发现结果是一样的。也是会全局改变。具体代码如下:
但是用haskell实现了一个,完全符合预期的结果。
main = do
let funcs = [(\n -> n + i) | i <- [0..9] ]
let x0: x1 : x2: x3: xs = funcs
return (x3 5)
返回结果是8。
看来Python对FP的支持还是比不上Haskell这种正统的函数式语言。
个人觉得如果Python要发展FP的话,可以考虑如下解决方案:区别本地变量和闭包变量。当声明函数的时候将闭包变量拷贝一份到本地,同时保留指向原闭包对象的引用。在搜索名字的时候,始终都是先搜索本地变量,再搜索本地闭包变量副本,再搜索全局变量。当需要修改的时候,如果是本地变量就直接修改。如果是闭包变量的时候,将原来闭包真正指向的对象进行修改,同时覆盖掉本地的闭包副本。
这个方法只是暂时的考虑,没有仔细的推敲。乍看之下似乎可以解决问题。
不过,Python毕竟是OO的语言。没有Haskell或者Lisp那种天生的作用域的控制能力。唉。那就用OO的方式来搞Python把。

